

If you're searching "how to A/B test cold emails," you're not really trying to learn what a split test is.
You're trying to get more real replies, book more qualified meetings, and stop guessing which subject line or CTA actually works. You want clean tests you can trust, even with low response rates and tracking that's gotten messy in the Apple Privacy era.
This is about optimizing cold outreach for real business outcomes, not vanity metrics.
This guide is the complete system. Not theory. The practical framework we'd use if we had to rebuild cold email optimization from scratch.
Why Most Cold Email A/B Tests Fail (And How to Fix It)

Most cold email A/B tests fail for one of four reasons:
They optimize the wrong thing. Opens instead of replies. Replies instead of qualified replies. The metric you choose determines whether you win or just look like you did.
They're statistically underpowered. Tiny tweaks tested on tiny samples produce random "wins" that never replicate. At baseline reply rates of 1-3%, detecting meaningful lifts requires thousands of emails per variant.
They're not actually controlled. Different inboxes. Different days. Different segments. Different deliverability. The only reason B outperforms A is because you accidentally gave B the better conditions.
They ignore modern inbox reality. Tracking is messy, and mailbox providers got stricter in 2024-2025.
Two shifts matter directly for A/B testing:
Open rates are less trustworthy than most people think. Apple Mail Privacy Protection can prefetch content and trigger tracking in ways that don't reflect a human reading your email. Nearly half of email clients are potentially affected by this, which means your "open rate" might include zero actual opens.
That's why our practical breakdown of why open rates mislead focuses on what to track instead: replies and meetings.
Deliverability requirements tightened. Gmail's sender guidelines (effective Feb 1, 2024) require authentication and keeping spam rates below 0.3%. If you send more than 5,000 emails daily to Gmail, you must have SPF, DKIM, DMARC, and one-click unsubscribe for certain message types. Our complete deliverability guide breaks down these requirements.
Microsoft announced similar requirements for high-volume senders to Outlook.com domains (enforced April 2025), with rejection language for domains sending over 5,000 emails daily without proper authentication.
If your tests don't account for tracking noise and deliverability guardrails, you'll learn the wrong lesson.
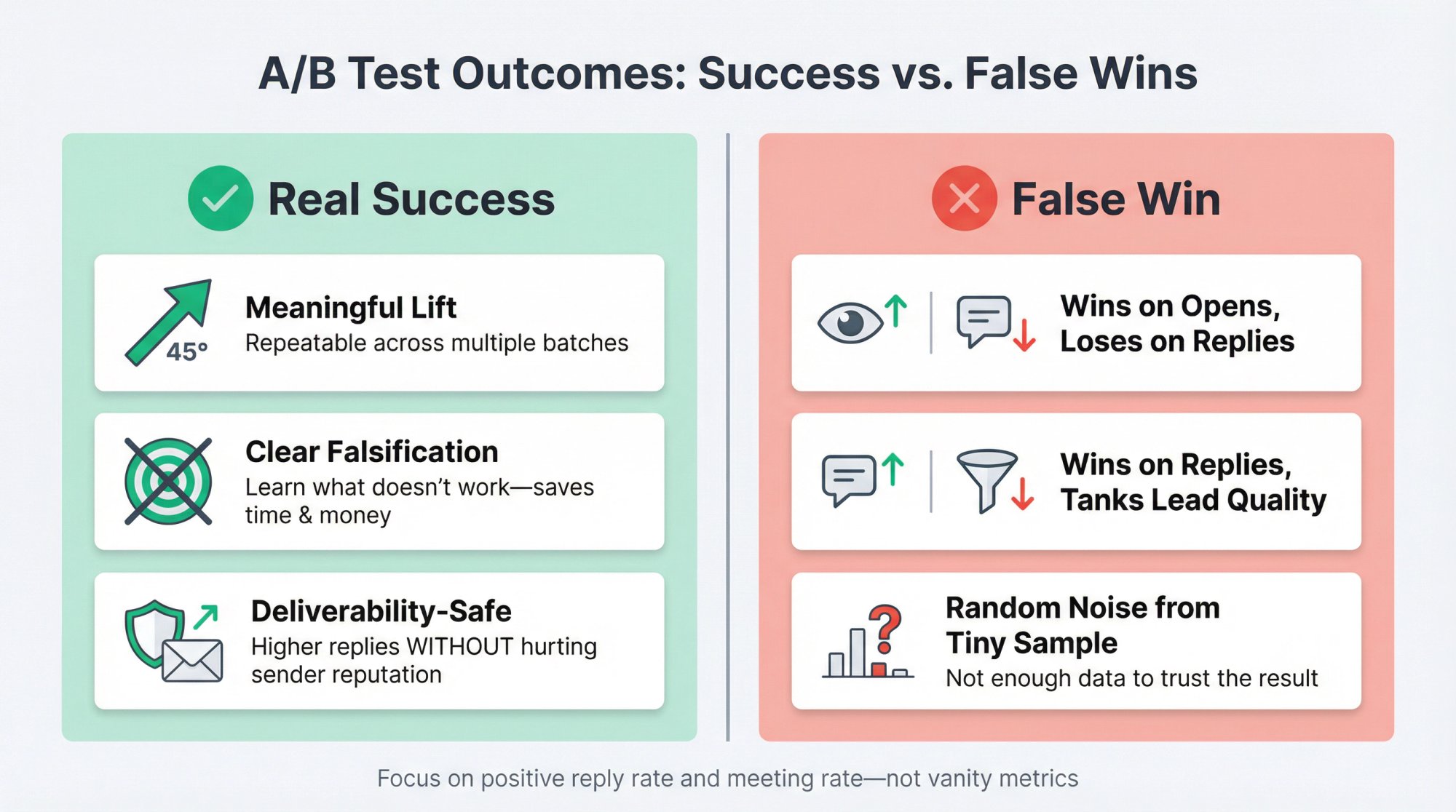
What Good A/B Test Results Look Like (Success Metrics)
A cold email A/B test is successful when it produces one of these outcomes:
• A meaningful, repeatable lift in positive reply rate (or meetings) that holds across at least one more batch
• A clear falsification: "This angle doesn't work for this segment" (which saves money and time)
• A deliverability-safe improvement: higher replies without increasing bounces, spam complaints, or negative replies
A test is not successful if it "wins" on opens but loses on replies. Or wins on replies but tanks lead quality. Or wins on a tiny sample that never replicates.
How to Choose the Right Metrics for Cold Email Tests

The Metrics That Actually Matter in Cold Outbound
Use a simple hierarchy:
Primary metric (fast feedback, hardest to fake):
• Positive reply rate = positive replies ÷ delivered leads
Secondary metric (what you ultimately want):
• Meeting rate = meetings booked ÷ delivered leads
• Or pipeline rate if you can attribute it cleanly
Guardrails (stop rules):
• Hard bounce rate
• Spam complaint rate (where available)
• Unsubscribe rate (if you include it)
• Negative reply rate (especially "stop", "spam", "remove me", "reporting" language)
Why "delivered leads" instead of "emails sent"? Because bounces aren't "attempts." They're reputation damage and noise.
Our deliverability content emphasizes this: deliverability is the foundation, not a side quest.
Should You Track Open Rates at All?
You can, but treat opens as diagnostic telemetry, not a KPI.
If opens are near zero, something may be blocked. If opens are high but replies are dead, your targeting, offer, or CTA is likely off. If opens are high because of privacy prefetch, they might not mean anything.
Reply rate is what matters for cold email success.
What to Test in Cold Emails (Priority Order)
Most people start by testing subject lines because it's easy.
That's usually wrong.

Subject lines can matter, but the biggest lifts in cold email usually come from these, in order:
Priority | Test Variable | Why It Matters |
|---|---|---|
1 | Targeting / ICP slice | Who you email determines baseline relevance |
2 | Offer | What you're giving them, why it's worth time |
3 | Angle / positioning | The story you tell about the problem and solution |
4 | CTA | The specific next step you're asking for |
5 | Proof | Why you, why now (case studies, results, authority) |
6 | Personalization method | Which signal you use and how you use it |
7 | Subject line | Gets the open, but doesn't close the reply |
8 | Send timing | When the email arrives in their inbox |
If you're getting under 1% replies and you're testing commas, you're optimizing decoration on a building with no foundation.
Our cold email best practices guide is basically a checklist of these higher-leverage fundamentals. For specific tactics, see our guides on email copywriting, effective first lines, and high-converting templates.
What Is an A/B Test? (First Principles Explained)
An A/B test is a randomized controlled experiment.
That sounds fancy, but the idea is simple:
• You have two versions: A and B
• You randomly assign similar prospects to each version
• You measure outcomes
• The only reason B should outperform A is because of the change you made
If you don't randomize, you're not testing. You're just comparing two different groups of people.
Cold Email-Specific Twist: The Unit Is the Lead, Not the Email
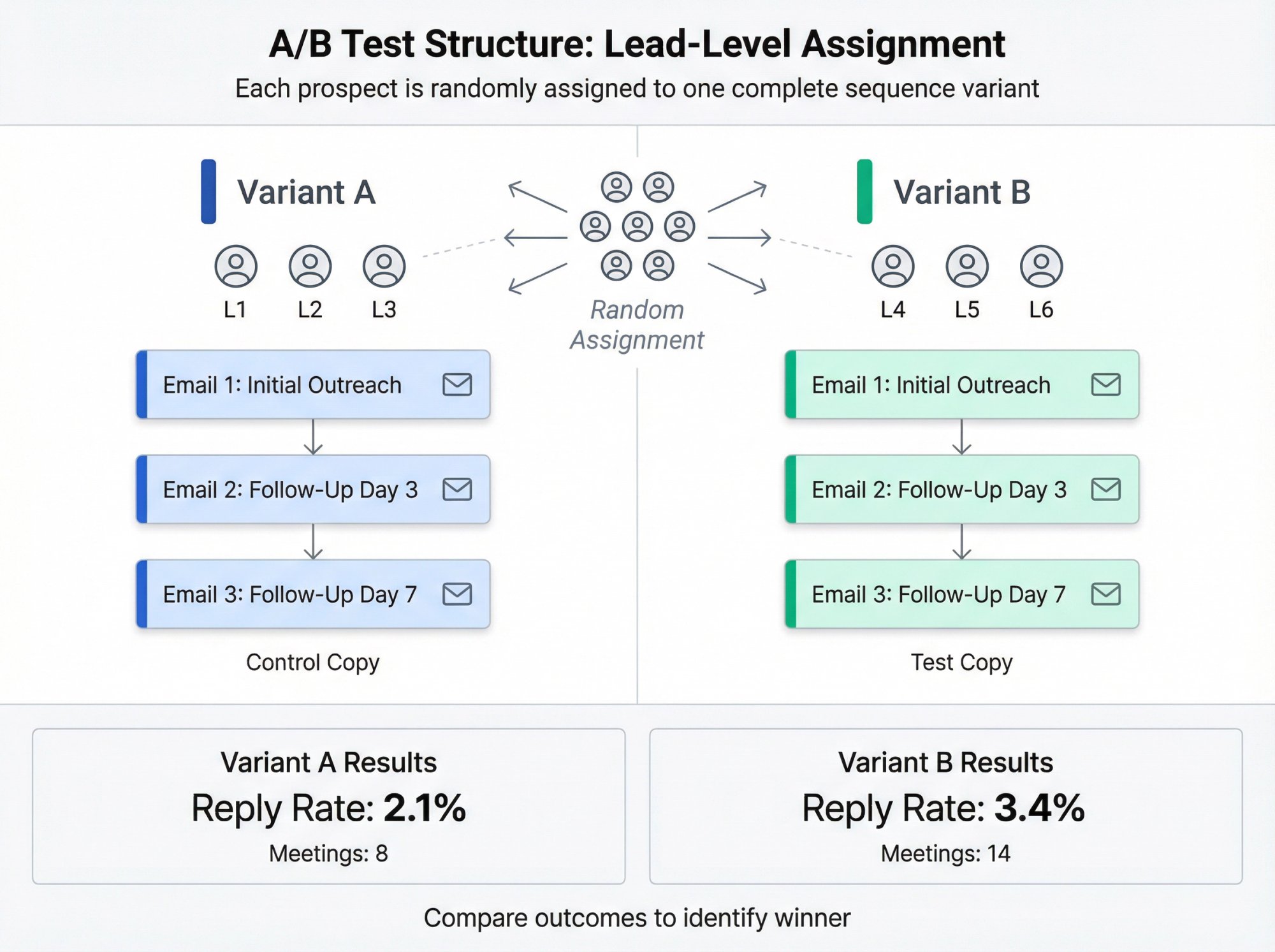
If you run sequences (you do), then the correct unit is:
One prospect = one assignment to A or B
That prospect gets the full sequence version for that variant.
Why? Because follow-ups drive a huge share of replies. Research analyzing millions of cold emails found 55% of replies came from follow-ups, which is why our follow-up tactics guide emphasizes multiple strategic touchpoints for best results.
So if you only compare first-email replies, you're often measuring the wrong thing.
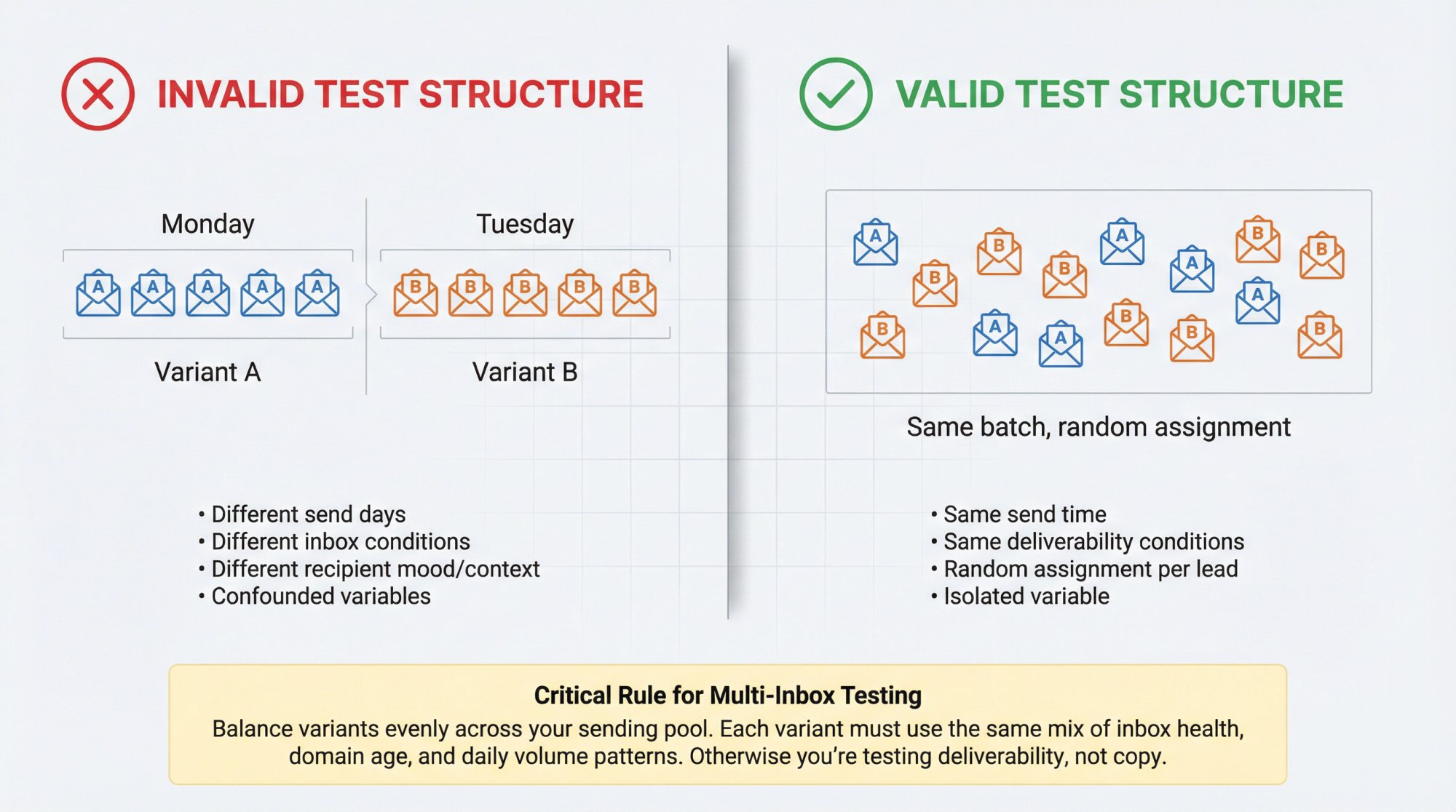
How to Structure a Valid Cold Email A/B Test
Here's the structure you need for a clean cold email A/B test.
Write a Test Hypothesis (So You're Not Just "Trying Stuff")
Use this format:
If we change X for Y segment,
then we expect Z outcome,
because (reason rooted in buyer psychology or relevance).
Example:
If we change the CTA from "Want to hop on a call?" to a binary "Worth exploring?" for heads of RevOps at 50-200 person SaaS companies, then positive reply rate will increase, because the decision cost is lower and the reply requires less commitment.
If you can't write the "because," you're not testing a strategy. You're rolling dice.
Change One Thing (Seriously, One)
If you change subject line and first line and CTA, you don't know what caused the lift.
If you must change multiple elements, treat it as a package test: "New offer + new CTA" vs control. That's valid, but label it honestly. Learn more about structuring prospecting emails for cleaner tests.
Randomize Properly (Don't Split by Time)
Bad split:
Monday batch gets A, Tuesday batch gets B.
Why it's bad:
Different day, different inbox placement, different mood, different everything.
Good split:
Within the same batch, randomly assign each lead to A or B.
Balance Across Inboxes and Domains (Especially at Scale)
If you're sending from multiple inboxes, you must avoid this trap:
• Variant A accidentally gets more sends from "healthy" inboxes
• Variant B gets more from "new" or "degraded" inboxes
• You think the copy won, but deliverability won
Fix:
Make sure each variant is evenly distributed across the same sending pool (same domains, same inbox age bands, same daily volume pattern).
Our infrastructure is built around controlling sender reputation, because otherwise you can't reliably interpret results. We use 350 to 700 Microsoft US IP inboxes depending on the tier, specifically to maintain consistent deliverability across tests.
Lock Timing (Or Explicitly Test Timing)
Send time is a variable. Either keep it constant across both variants, or make send time the single variable you're testing.
Our timing research explains how to think about "best time" as a reply metric, not an open metric.
Cold Email Deliverability Requirements for Testing

Modern mailbox providers care about authentication, complaint rates, and sender behavior. That's not theory. It's explicitly stated in sender requirements.
Gmail Deliverability Guardrails (2024+)
Google's Email Sender Guidelines state:
• Starting Feb 1, 2024, all senders must meet baseline requirements
• If you send more than 5,000/day to Gmail, additional requirements apply (SPF, DKIM, DMARC)
• Keep spam rates in Postmaster Tools below 0.3%
• Marketing/subscribed messages must support one-click unsubscribe and include a visible unsubscribe link in the body (for the 5,000+/day requirement set)
What this means for A/B testing:
If one variant increases spam complaints even slightly, it can hurt inbox placement quickly. Always monitor deliverability signals while running tests.
Outlook.com Consumer Guardrails (2025+)
Microsoft's Outlook.com requirements for high-volume senders (to outlook.com, hotmail.com, live.com) include:
• Threshold: domains sending over 5,000 emails/day
• Must comply with SPF, DKIM, DMARC
• Enforcement includes routing to Junk and eventually rejecting messages
What this means for A/B testing:
Keep authentication fixed during tests. If you change DNS or sending infrastructure mid-test, you just invalidated your own experiment.
Basic Cold Email Deliverability Stop Rules
Use these as operational defaults:
Hard bounce rate > 2%: Stop and fix list quality before you "optimize copy." Our sender reputation guide discusses bounce and reputation thresholds. Also see our guides on reducing bounce rates and waterfall enrichment for data quality.
Sudden spike in negative replies: Stop and evaluate relevance and compliance.
Spam complaint signal: If you have Postmaster Tools data, treat spikes as an emergency.
And if you're not properly authenticated, go fix that first. Our SPF/DKIM/DMARC setup guide is a solid reference. For comprehensive infrastructure setup, see our cold email infrastructure guide.
Sample Size Requirements for Cold Email A/B Tests

Here's the math reality in cold email:
Reply events are rare. Rare events have high variance. High variance means you need more data to be confident.
A Simple Intuition
If you flip a coin 10 times and get 7 heads, you wouldn't declare the coin "biased."
Cold email A/B testing is the same. If you have 200 sends and get 4 replies vs 7 replies, that might be noise.
Cold Email Benchmark Ranges (So You Don't Assume Fantasy Baselines)
Industry research (last updated Jan 13, 2026) states a widely accepted average cold email response rate of ~1% to 5%, but notes huge variation by context.
That range matters because sample size requirements explode at low baselines.
Sample Size Table (95% Confidence, 80% Power)
Approximate number of delivered leads per variant required to detect a lift:
Baseline reply rate | Lift you want to detect | Needed per variant (approx) |
|---|---|---|
1% | +25% (to 1.25%) | 27,937 |
1% | +50% (to 1.5%) | 7,750 |
1% | +100% (to 2.0%) | 2,319 |
3% | +25% (to 3.75%) | 9,100 |
3% | +50% (to 4.5%) | 2,518 |
3% | +100% (to 6.0%) | 749 |
5% | +25% (to 6.25%) | 5,333 |
5% | +50% (to 7.5%) | 1,471 |
5% | +100% (to 10.0%) | 435 |
Read that again.
If you're at a 1% reply rate and trying to detect a 25% relative lift, you need ~28,000 delivered leads per variant.
This is why the highest-value A/B tests are usually big, strategic changes (offer, targeting, CTA), not microscopic copy edits.
What to Do If You Don't Have Enough Volume for Statistical Significance
You have three sane options:
1. Increase effect size: Test bigger changes.
2. Use directional decision rules (practical, but honest).
3. Use adaptive testing (multi-armed bandits) so you learn while allocating more traffic to winners. Marketing science research has explored adaptive experimentation approaches for email testing.
If you want a practical rule that works at low volume:
Run until each variant has at least 1,000 delivered leads, or until you have at least 30-50 total replies across both variants (whichever comes later).
Only declare a winner if:
• The lift is large (at least 30-50% relative)
• It holds across two consecutive batches
You're trading statistical purity for operational speed, but you're doing it consciously.
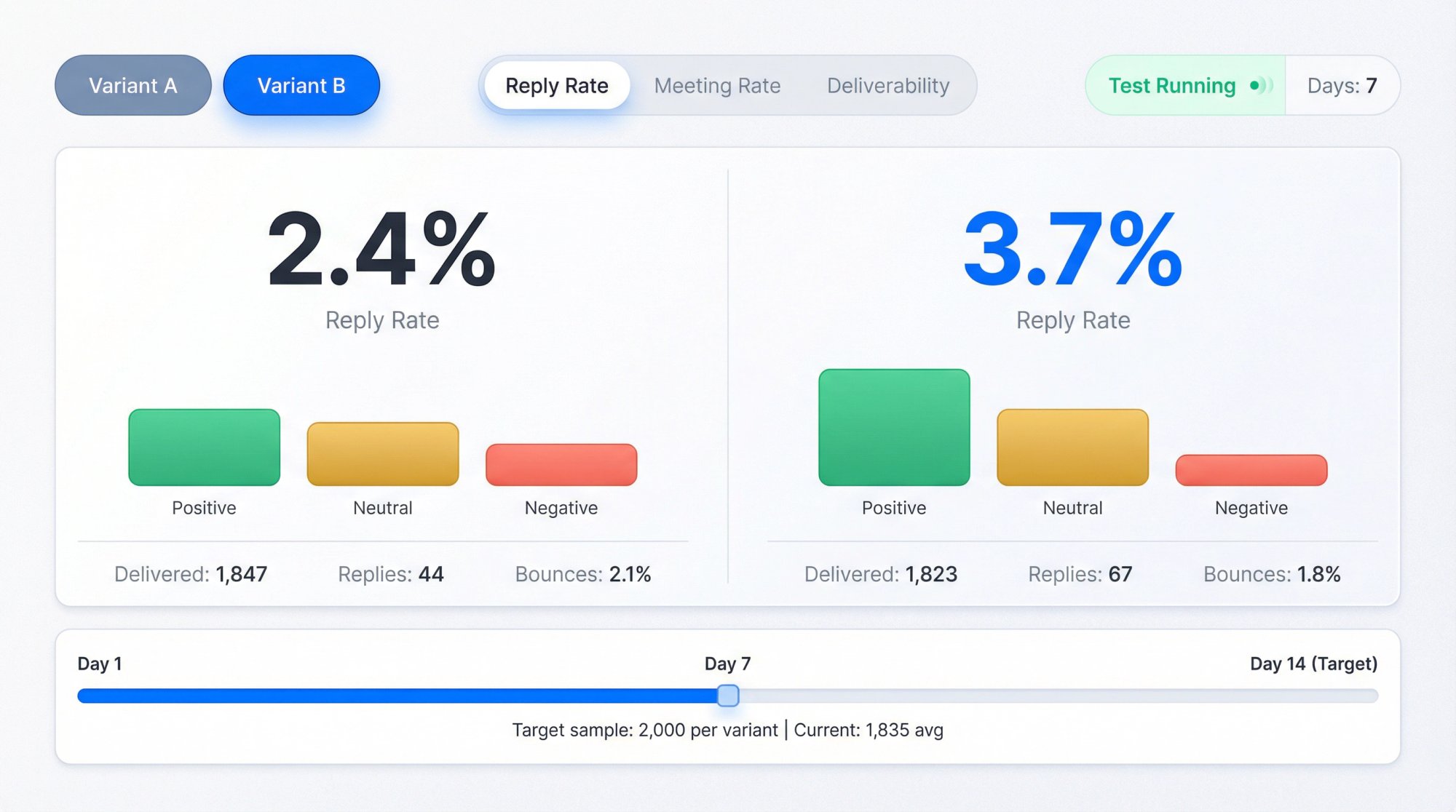
How to Analyze A/B Test Results Correctly
Clean Your Denominator
Before computing rates, exclude:
• Hard bounces
• Duplicates
• Obvious junk targets (if your list had issues)
Use "delivered leads" consistently.
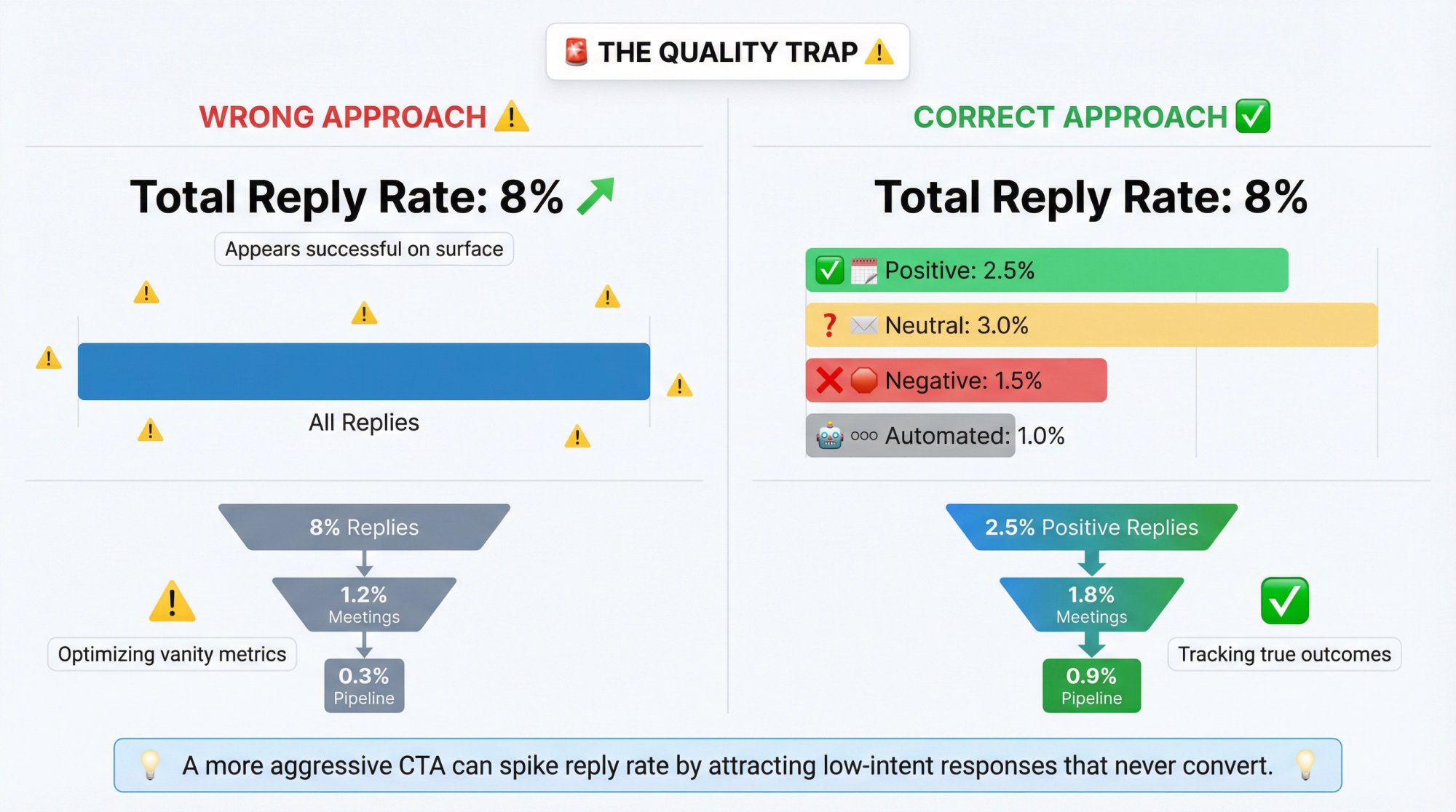
Use Outcome Tiers (Not Just "Replies")
Replies aren't equal.
Bucket them:
Positive: interested, yes, referral, scheduling
Neutral: questions, "send more info"
Negative: no, stop, unsubscribe, annoyed
Automated: OOO, auto-responders
Your "winner" should ideally improve positive replies, not just total replies.
Watch for the Quality Trap
A "more aggressive" CTA can spike reply rate by attracting low-intent "send me info" responses that never convert.
Always compare:
• Positive reply rate
• Meeting rate (with lag)
Don't Stop Tests the Second B Looks Better
Early results are noisy. Stopping early increases false wins (winner's curse).
A better stop rule:
Stop when you hit your planned sample, or stop if a variant violates deliverability guardrails.
Copy-Paste A/B Testing Framework for Cold Email
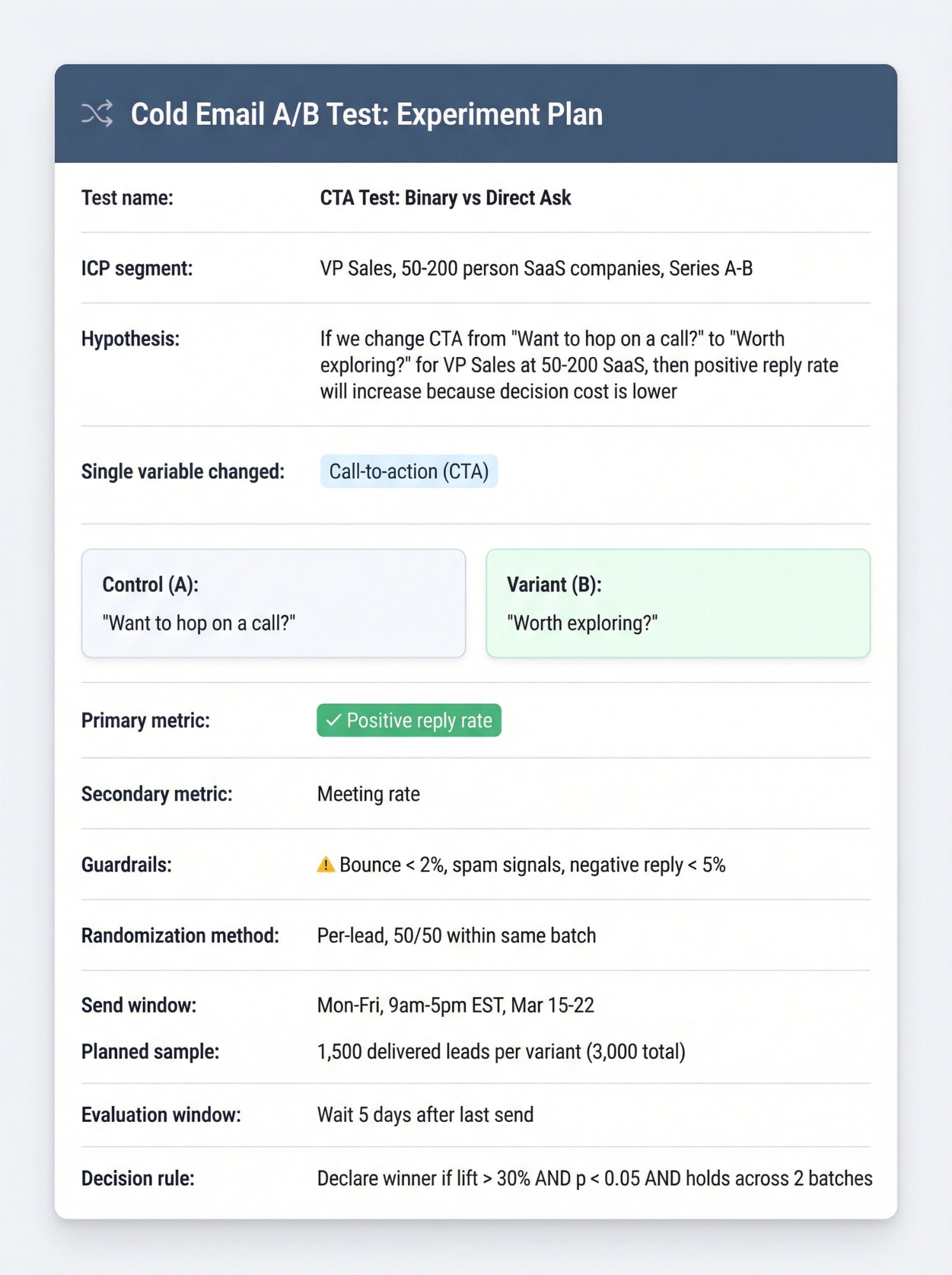
The One-Page Experiment Plan
Test name:
ICP segment:
Hypothesis:
Single variable changed:
Control (A):
Variant (B):
Primary metric: Positive reply rate
Secondary metric: Meeting rate
Guardrails: bounce %, spam signals, negative reply %
Randomization method: per-lead, 50/50 within same batch
Send window: (days + times)
Planned sample: X delivered leads per variant
Evaluation window: wait Y days after last send before declaring winner
Decision rule: (write it before you start)
The Experiment Log (Minimum Fields)
• Date launched
• Segment definition
• Offer and CTA
• Variant text (store exact copy)
• Deliverability notes (any infrastructure changes, warmup status)
• Results after evaluation window
• Decision
• Next iteration
If you do nothing else, do this. The log compounds learning faster than any single test.
High-Impact Cold Email A/B Tests Worth Running
Below are test ideas that are actually worth your time.
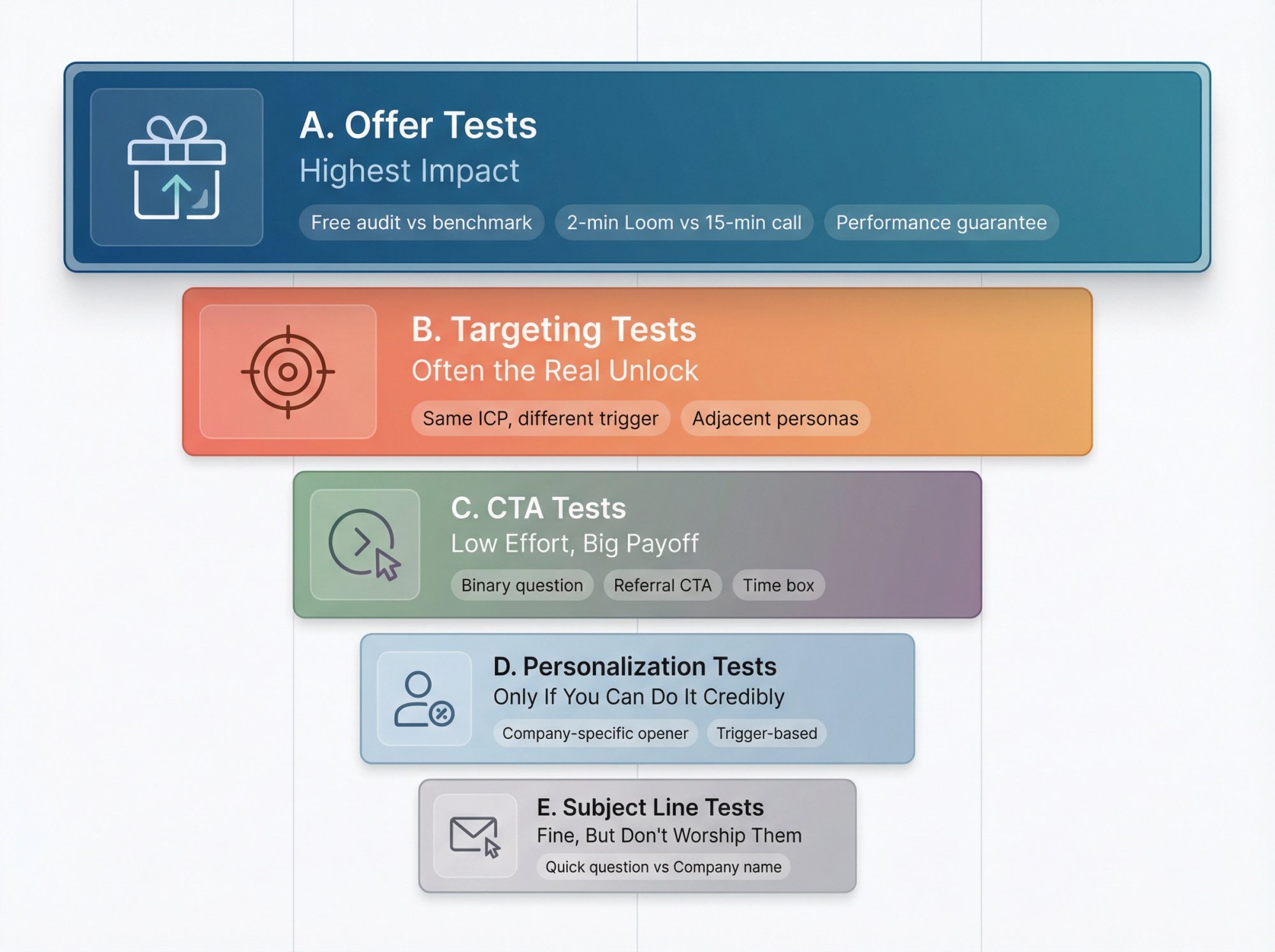
A. Offer Tests (Highest Impact)
1. "Free audit" vs "benchmark report"
2. "2-minute Loom" vs "15-min call"
3. "I found 3 quick wins" vs "here's the problem we solve"
4. Outcome framing: "reduce churn" vs "increase expansion" (same product, different value)
Why these work: You're testing willingness to allocate attention, not syntax. Learn more about effective sales email writing.
B. Targeting Tests (Often the Real Unlock)
1. Same ICP, different trigger:
• Recently hired role
• Funding
• Tech stack change
2. Two adjacent personas:
• VP RevOps vs VP Sales
• IT director vs security lead
Why these work: Relevance is the multiplier. Testing copy without testing relevance is like tuning a guitar that's missing strings. Our guides on list building and prospect targeting cover the fundamentals.
C. CTA Tests (Low Effort, Big Payoff)
1. Binary question: "Worth a quick look?" vs "Open to a chat?"
2. Referral CTA: "Who owns this?" vs direct ask
3. Time box: "15 mins next week?" vs "this quarter?"
D. Personalization Tests (Only If You Can Do It Credibly)
1. Company-specific opener vs role-specific opener
2. Trigger-based opener vs generic opener
3. "Saw X" vs "Noticed Y" (signal strength)
Our best practices guide emphasizes personalization beyond first name. For implementation, see AI for sales prospecting and social proof techniques.
E. Subject Line Tests (Fine, But Don't Worship Them)
Test subject lines when:
• Deliverability is healthy
• Body copy is already solid
• You're trying to optimize visibility and trust
Test pairs:
• "Quick question" vs "Question about {{Company}}"
• "{{Company}} + idea" vs "Idea for {{Company}}"
• No subject personalization vs light personalization
Just don't pretend opens are your ground truth.
Common Cold Email A/B Testing Mistakes to Avoid
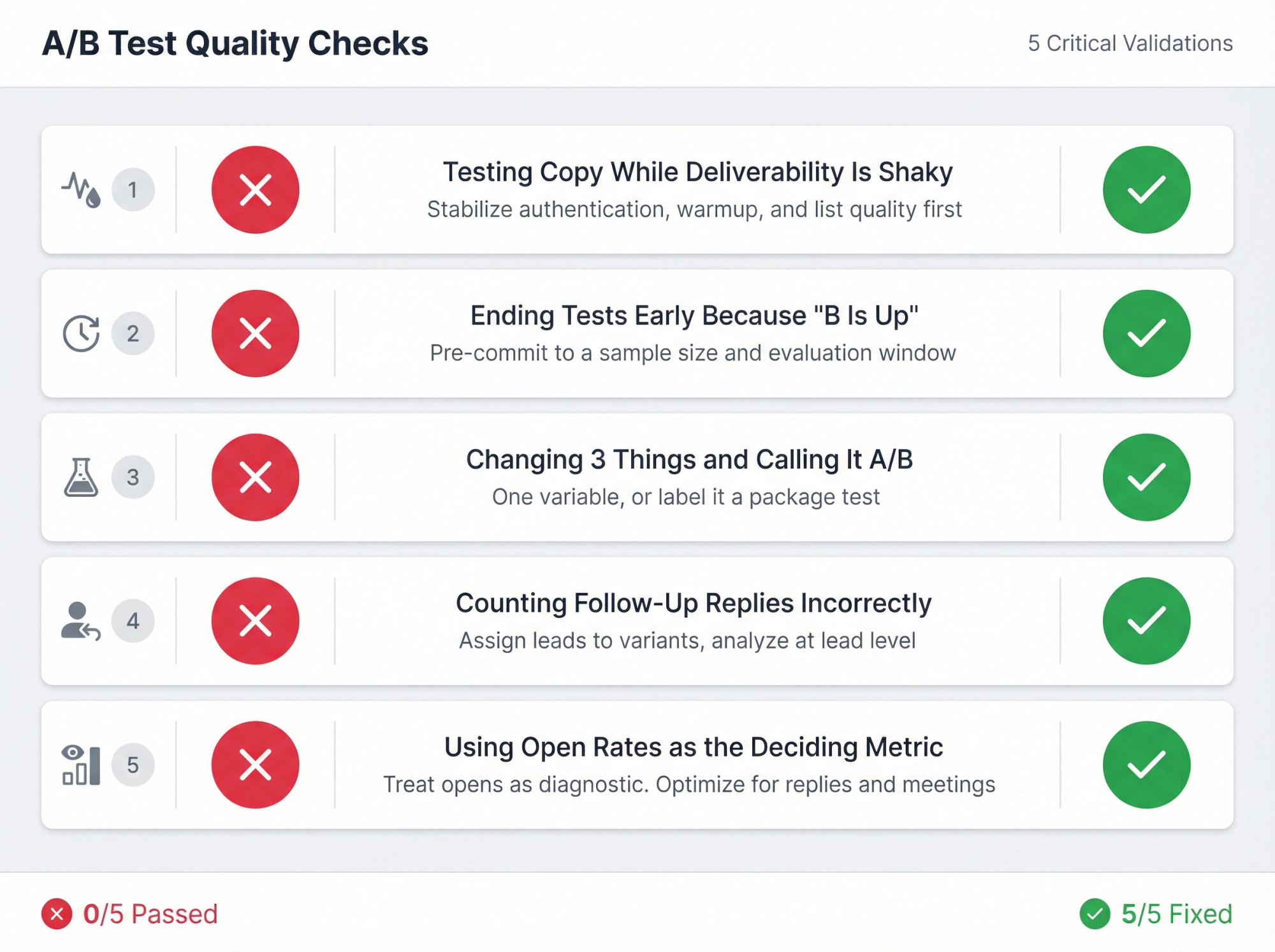
Common Cold Email A/B Testing Mistakes to Avoid
Mistake 1: Testing Copy While Deliverability Is Shaky
Fix: Stabilize authentication, warmup, and list quality first.
Gmail and Outlook both explicitly require strong authentication for high-volume senders. See our guides on email warmup, fixing spam issues, and domain warming.
Mistake 2: Ending Tests Early Because "B Is Up"
Fix: Pre-commit to a sample size and evaluation window.
Mistake 3: Changing 3 Things and Calling It A/B
Fix: One variable, or label it a package test.
Mistake 4: Counting Follow-Up Replies Incorrectly
Fix: Assign leads to variants, analyze at lead level.
Research on follow-up data shows why proper email sequences matter for accurate testing.
Mistake 5: Using Open Rates as the Deciding Metric
Fix: Treat opens as diagnostic. Optimize for replies and meetings.
Apple's privacy changes are the core reason opens mislead.
How Outbound System Handles A/B Testing
Most cold email A/B testing fails because infrastructure isn't controlled. You can't test strategy when deliverability is unstable.
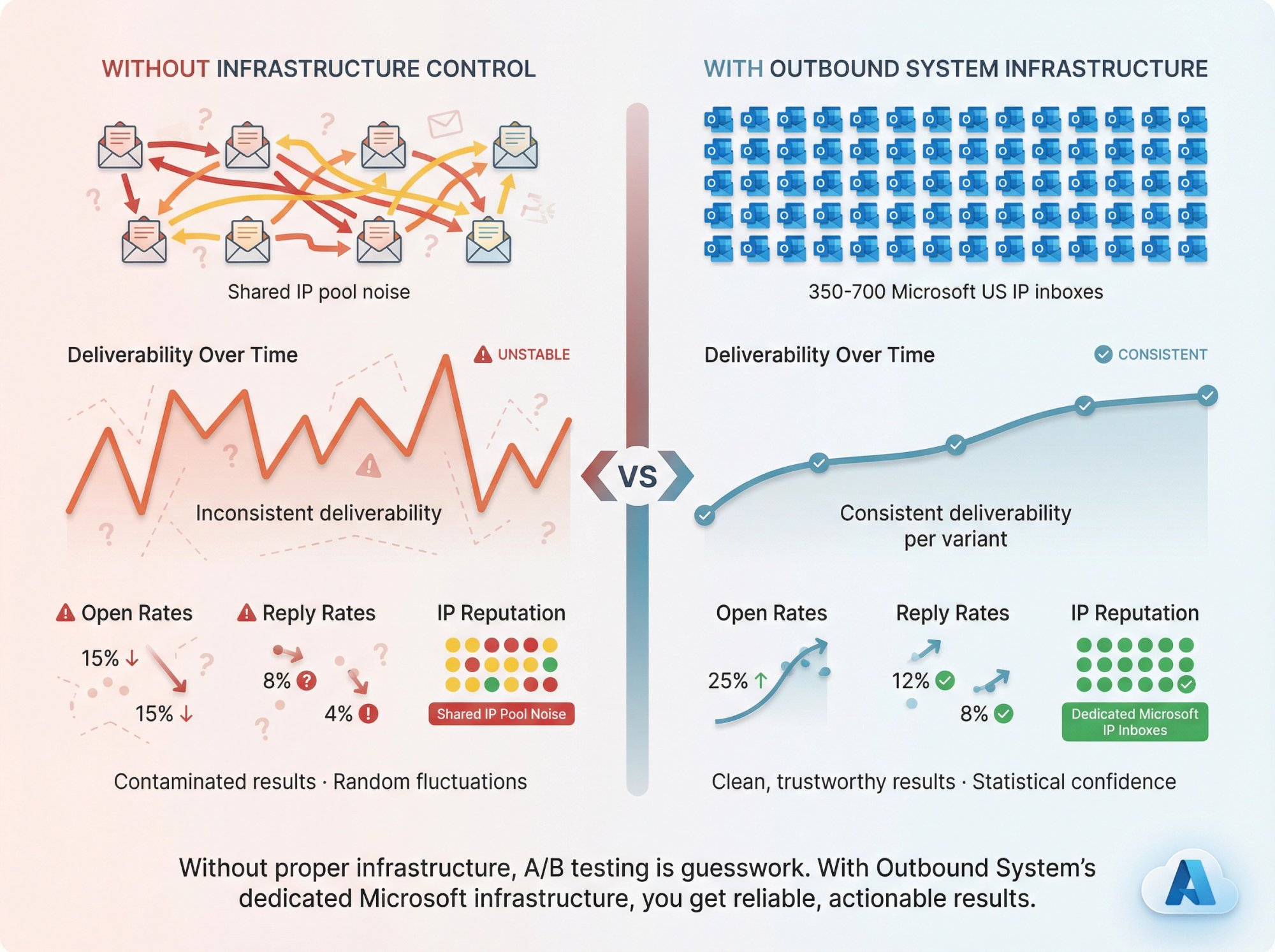
At Outbound System, we built the platform to eliminate infrastructure variables so you can actually learn from tests.
The Infrastructure Advantage
We use 350 to 700 Microsoft US IP inboxes (depending on your plan) spread across dedicated infrastructure. This means:
No shared IP pool noise. Your test results aren't contaminated by other senders' reputation issues.
Consistent deliverability per variant. Each test version gets evenly distributed across the same sending pool, same warmup status, same domain reputation.
Volume distribution that mimics natural patterns. Low per-inbox send volumes avoid spam filtering while maintaining scale. Learn more about Microsoft Azure infrastructure.
Data Quality as a Prerequisite
Our 9-step waterfall enrichment and triple-verified email data make sure bounces don't wreck your tests. We combine:
• Syntax validation
• SMTP ping verification
• Historic bounce data analysis
• Engagement signal evaluation
Clean data means you're testing messaging, not list quality.
Built for Testing
Every plan includes:
• Unlimited campaigns (test as many variants as you need)
• Built-in A/B testing with automatic randomization
• Real-time metrics showing positive vs negative vs neutral replies
• Unified inbox for managing responses
• Dedicated account strategist who helps design tests and interpret results
Our Service Plans
Feature | Growth Plan | Scale Plan |
|---|---|---|
Price | $499/month | $999/month |
Microsoft US IPs | 350 | 700 |
Monthly emails | 10,000 | 20,000 |
Unique leads/month | 5,000 | 10,000 |
AI personalization | ✓ | ✓ |
9-step enrichment | ✓ | ✓ |
A/B testing | ✓ | ✓ |
Dedicated strategist | ✓ | ✓ |
CRM integrations | ✓ | ✓ |
Month-to-month | ✓ | ✓ |
Both plans deliver 98% inbox placement and 6-7% response rates on average across our client base of 600+ B2B companies.
We've sent 52 million+ cold emails, generated 127,000+ leads, and helped close $26 million in revenue. See our case studies for specific results and client testimonials for feedback.
Why Infrastructure Matters for Testing
When you test with Outbound System, you know the results reflect your messaging decisions, not random deliverability fluctuations.
You can focus on what to say, not whether it'll land in inbox or spam.
That's the difference between guessing and knowing. Book a free consultation to discuss your testing strategy.
FAQ
How Many Versions Should I Test at Once?
Start with A/B. Multivariate testing explodes your sample size needs and increases false wins unless you have massive volume.
How Long Should I Run a Cold Email Test?
Long enough to send your planned sample and allow replies to come in (especially after follow-ups).
A practical default is wait 3-7 business days after the last touch before declaring a winner.
Should I Test Subject Lines Using Opens Anyway?
You can test subject lines using opens as a directional check, but don't treat it as truth. In 2026, opens are too distorted by Apple Mail Privacy Protection to be your primary decision metric.
What's a "Good" Reply Rate?
Benchmarks vary, but industry research cites a widely accepted average of ~1% to 5% across cold emails. Our cold email best practices focus on the fundamentals that drive these results.
Treat benchmarks as context, not a verdict. Your segment and offer matter more than averages.
What If I Don't Have Enough Volume for Statistical Significance?
Test bigger changes (offer, targeting, CTA) that produce bigger differences. Or use directional decision rules with smaller confidence: run until 1,000+ delivered per variant or 30-50 total replies, and only declare a winner if the lift is large (30-50%+) and holds across two batches.
Should I Test on My Whole List or a Subset First?
If your list is large (10,000+ prospects), you can test on a subset (20-30% of list) to validate before rolling out the winner. If your list is small, test on the whole list to get enough data. Learn more about email segmentation for better testing.
How Do I Handle Sequences in A/B Tests?
Assign each lead to a variant (A or B) and keep them in that variant for the entire sequence. Don't mix variants across follow-ups. Analyze results at the lead level (did this lead reply?) not email level (which email got a reply?).
The One Sentence That Should Guide Your Whole Testing Strategy
If your A/B test doesn't change something big enough to beat noise, you're not learning. You're gambling.
So test bigger levers first:
• Targeting (learn how to build lists)
• Offer (see cold emailing strategies)
• CTA
• Positioning
Then refine:
• Structure (email structure guide)
• Personalization (spintax for variation)
• Subject lines
• Timing (best send times)






